

H2 Quick Start
Hatbox has two distinct parts: the core library and a Geotools DataStore. The core library can be used entirely independently of the Geotools DataStore. This quick start will use only the core library to get data into your new Hatbox spatialized table and to issue spatial queries on it.
Installation
The quickest installation is to download hatbox-ui.jar . It is an executable jar with all dependencies included. We will use it to create a local server so that you can use your favourite SQL client (eg SQuirreL) to browse the database objects we create.
Start as java -jar hatbox-ui.jar (or simply double click the file). On the Connection tab select your h2
driver. You may also select the H2 upgrade jar to automatically upgrade a 1.1 database to the 1.2 ODS (on disk format).
The details are here.
Now enter a connection URL and press connect.
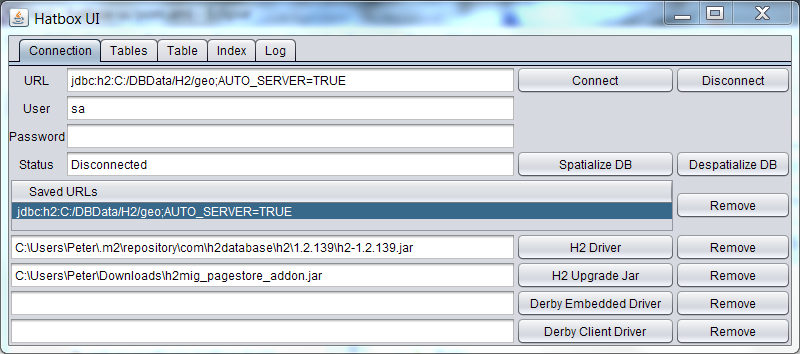
Note the AUTO_SERVER=TRUE option on the URL. This allows you to create a connection to the server with your favourite SQL client using the same URL
Spatialize Database
The first thing to do is 'spatialize' the database. This amounts to creating a set of common function
aliases that table triggers will later use. These objects will be created in the PUBLIC schema. Just press
the Spatialise DB button.
You should now be able to see 8 function aliases in the PUBLIC schema. In SQuirrel these can be seen
in INFORMATION_SCHEMA/SYSTEM_TABLE/FUNCTION_ALIASES
Create a table
Now create a spatial table in your test database. Because Hatbox is a user-space tool, the table you create is a perfectly ordinary H2 table. There are a couple of requirements of it:
- It must have a primary key
- The primary key must be SMALLINT, INTEGER, BIGINT or IDENTITY
- It must have a column to store the geometry that is BINARY or BLOB
create table T1 ( ID identity, NAME varchar (20), GEOM varbinary (200))
Now go to the Tables tab in Hatbox UI and TI is listed. Select T1 and we now have a T1 tab.
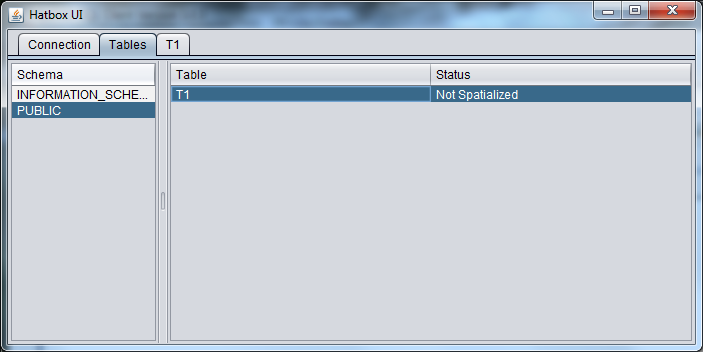

Spatialize the table
Select a Geometry type (eg LINESTRING), SRID (epsg code eg 4326 for WGS84), whether you wish to expose the PK as an attribute in Geotools, the maximum entries per index node (the default 49 gives a node size just under 2K) and a geometry column (eg GEOM). Press the Spatialize button.

In your query tool (eg SQuirreL) you should now be able to see two tables in the PUBLIC schema: T1 and T1_HATBOX. The T1_HATBOX table contains one row. This row is the index meta-data. You should never change data in the _HATBOX tables directly
Insert Data
The following program inserts a set of point features in the new table.
package test;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.DriverManager;
import com.vividsolutions.jts.geom.GeometryFactory;
import com.vividsolutions.jts.geom.Point;
import com.vividsolutions.jts.geom.Coordinate;
import com.vividsolutions.jts.geom.impl.CoordinateArraySequenceFactory;
import com.vividsolutions.jts.io.WKBWriter;
public class TestInsert {
public static void main(String[] args) throws Exception {
Class.forName("org.h2.Driver");
Connection conn = DriverManager.getConnection("jdbc:h2:C:/Data/hatbox;AUTO_SERVER=TRUE", null, null);
GeometryFactory geomFactory = new GeometryFactory();
CoordinateArraySequenceFactory factory = CoordinateArraySequenceFactory.instance();
Coordinate[] coord = new Coordinate[1];
WKBWriter writer = new WKBWriter();
PreparedStatement ps = conn.prepareStatement("insert into T1 (NAME, GEOM) values (?,?)");
ps.setString(1, "Test Point");
coord[0] = new Coordinate(145.0, -37.0);
ps.setBytes(2, writer.write(new Point(factory.create(coord), geomFactory)));
ps.execute();
coord[0] = new Coordinate(145.1, -37.1);
ps.setBytes(2, writer.write(new Point(factory.create(coord), geomFactory)));
ps.execute();
coord[0] = new Coordinate(145.2, -37.2);
ps.setBytes(2, writer.write(new Point(factory.create(coord), geomFactory)));
ps.execute();
coord[0] = new Coordinate(145.3, -37.3);
ps.setBytes(2, writer.write(new Point(factory.create(coord), geomFactory)));
ps.execute();
ps.close();
conn.close();
}
}
You should now be able to see 4 rows in table T1. There should be no change to the meta data row in T1_HATBOX.
Build Index
Press the Build Index button.
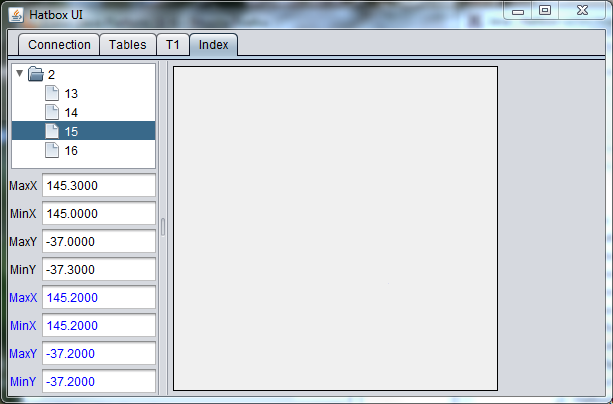
Table T1 is now identified as an INDEXED spatialized table. You should now be able to see 3 triggers on T1 that keep the index in sync with the data table. Also the index root node (table T1_HATBOX, ID = 2) should have been inserted. When more than 49 entries are inserted the root node will split and a new node will become the root of a tree of nodes.
Select the Index tab of Hatbox UI to see the index structure
Query
The following program selects point features that fall within a query envelope.
package test;
import java.sql.Connection;
import java.sql.Statement;
import java.sql.ResultSet;
import java.sql.DriverManager;
import com.vividsolutions.jts.io.WKBReader;
public class TestQuery {
public static void main(String[] args) throws Exception {
Class.forName("org.h2.Driver");
Connection conn = DriverManager.getConnection("jdbc:h2:C:/Data/hatbox;AUTO_SERVER=TRUE", null, null);
Statement stmt = conn.createStatement();
WKBReader reader = new WKBReader();
ResultSet rs = stmt.executeQuery("select ID, GEOM from T1 as t inner join " +
"HATBOX_MBR_INTERSECTS_ENV('PUBLIC','T1',145.05,145.25,-37.25,-37.05) as i " +
"on t.ID = i.HATBOX_JOIN_ID");
while (rs.next()) {
System.out.println(rs.getInt(1) + ":" + reader.read(rs.getBytes(2)));
}
rs.close();
stmt.close();
conn.close();
}
}
The output should display two of the four points that fall within the query envelope. This is the simplest type of query possible. Hatbox also supports queries with secondary filtering on all the common predicates (intersects, within etc).